Recently, I started streaming SQL Friday directly to YouTube. The speaker still connect to a Teams meeting and then I use OBS Studio to create scenes with components from the Teams call together with a Title bar etc, and stream from OBS Studio directly to YouTube.
Since I struggled a little bit with getting all the bits and pieces right (and perhaps I still have some tuning to do), I wanted to write this blog post, in case anyone search for a way to do the same.
First – setup NDI for your Teams computer
NDI, short for Network Device Interface, is a broadcasting technology that broadcasts streams from cameras and other devices to the local network. Teams has built-in capabilities for NDI broadcasts, but you will need some NDI drivers. These drivers can be downloaded from https://ndi.video/download-ndi-sdk/. Downloading the NDI SDK should be enough. You will need this software on the computer where you run your Teams client as well as on the computer where you run OBS Studio. In my case, it’s the same computer, but you may just as well connect to Teams from your laptop, and use OBS on a seperate production computer.
Once you have installed the SDK, you need to configure your Teams user, to allow it to broadcast with NDI. This is done in the Teams Admin portal, by changing existing or creating new meeting policy and assign it to the users who should be allowed to use NDI broadcast.
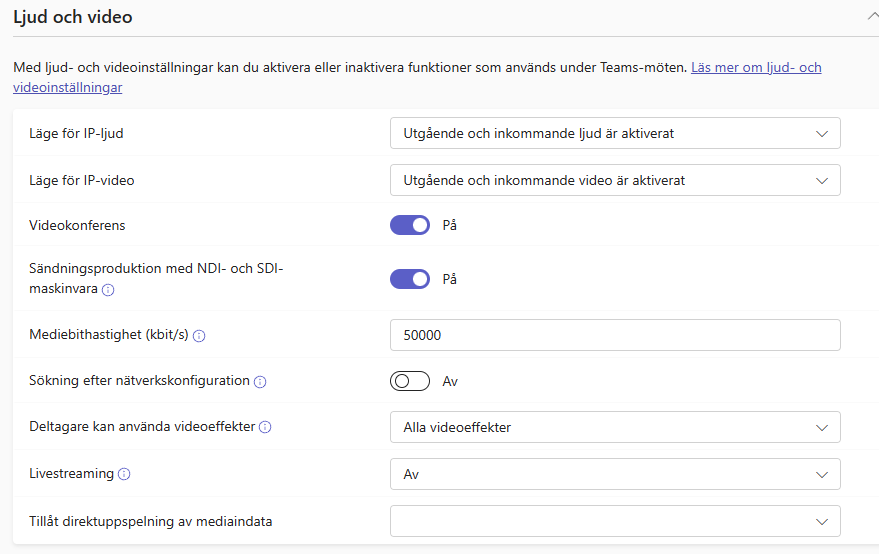
This admin-page is in swedish, but just open meeting policy and go down to Audio and Viewo and select the NDI/SDI-option.
Next step is to configure the Teams client.
SO FAR, NEW TEAMS CLIENT HAS VERY LIMITED SUPPORT FOR NDI BROADCASTS
So I stick to the classic/old Teams client. There, you enable NDI for yourself by clicking the three-dot-menu next to your profile picture, and select Settings. Under settings, you go to the App Permissions tab, and there you should find this setting.
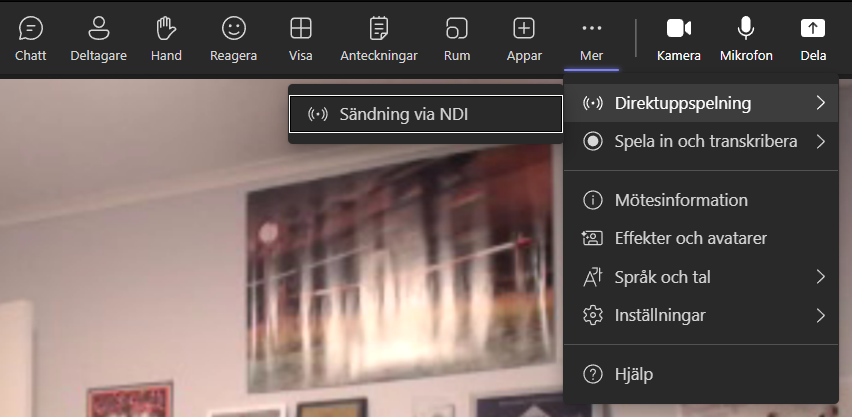
Now you’re almost done with the NDI setup in Teams. Last step is to start broadcasting when you’re in a meeting. So start the meeting, select “… More” and enable Broadcast via NDI under the Broadcast menu (above the recording menu). If you don’t see it, make sure your Teams admin have enabled NDI and that you yourself have enabled NDI for yourself in Teams.
Next up – configure NDI in your OBS Studio computer
For the computer where you run OBS Studio, you also need to install the NDI SDK (see the previous section). I went for the full Tools-suite, but that’s not really necessary. If you run OBS Studio on the same computer as Teams, you’re all done.
Once we have the NDI-SDK in our OBS Studio computer, we need to install the NDI-Plugin for OBS Studio. You can do that from the OBS Project Plugins forum.
Now we’re ready to start configuring our NDI sources. The easiest way to do it is to start a Teams call with someone, start the NDI broadcast in Teams and then go into OBS Studio to create a scene.
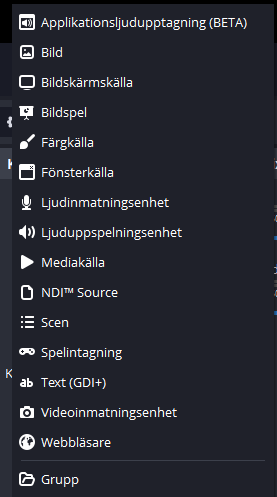
In your OBS Studio Scene, click the Plus sign to add a new source. This will bring up this menu:
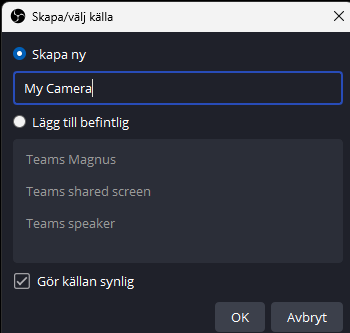
Again, swedish, but the symbols are universal. Select “NDI(tm)Source”Give the source a meaningful name and hit OK.After hitting OK, you will start configuring the source. If your Teams call is broadcasting with NDI, you will be able to select your own camera, other participants’s cameras and whatever is shared by any of the participants.
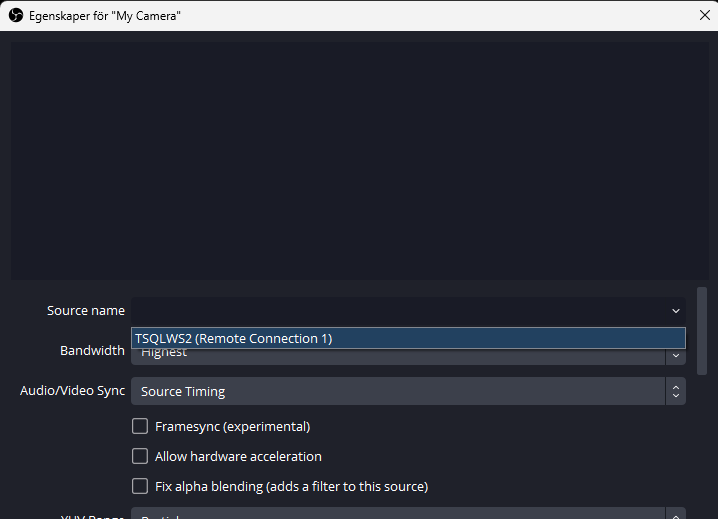
One thing I realised late into the game is the Audio Video sync settings of an NDI source. The default is “Source Timing”. Change it to “Network” and you will most probably notice a remarkable improvement in audio quality from your Teams call. Also the sync itself actually works. If you get this wrong, chances are your stream from OBS Studio will get the audio sources mistimed, which makes for a quite funny way to follow conversations between two parties…
Network is the way to go here.
For the rest, it’s going to come down to your creativity in setting up the scenes in OBS Studio. I will leave that up to you.
Lastly – stream to YouTube
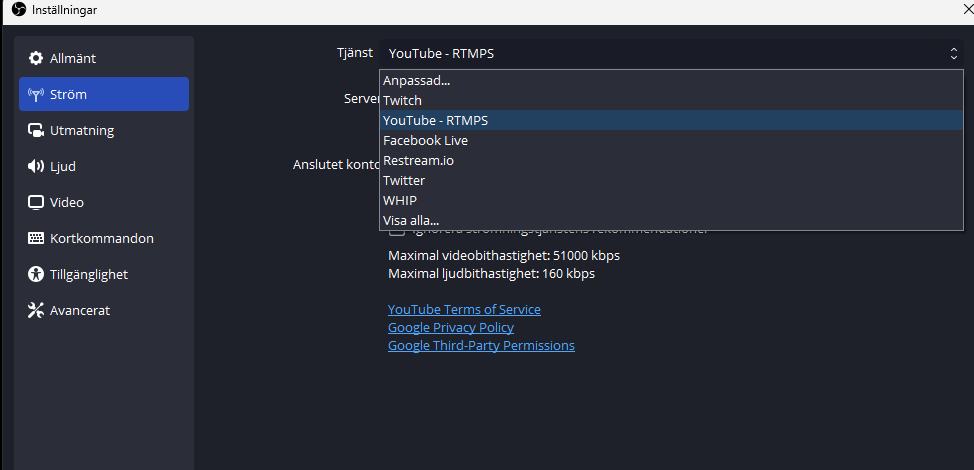
To stream to YouTube, you need a YouTube channel. If you already have that, you’re basically good to go. In OBS Studio, choose the stream settings over here.
So start by opening “Settings” and configure your Sterams.
Here you connect your YouTube account in OBS Studio, and then you can start creating or connecting to planned Live Streams.
With your YouTube account connected, you choose to manage streams in the lower right-hand corner of OBS Studio.
It’s “Hantera sändning” in swedish. You’ll figure out where that button is in whatever language you use.
Now you can either create a new Live-stream, or select an existing one from your connected YouTube account. The settings if you choose to create a new Live Stream are pretty much the same you will find in YouTube Studio, so I’m not going to explain them in detail. Once you’re done selecting or creating your Live Stream and select it, you’re ready to start streaming.
When you have selected a Live Stream to connect to, you can start streaming.
DONE! Or maybe not
I’m sure you, as I, will run into some technical difficulties with NDI/OBS Studio/YouTube. You can see my results, and how they evolve over time on my YouTube-channel. SQL Friday Season 8 is the first playlist where I started live streaming the event. (1) SQL Friday Season 8 – YouTube
Good luck! Let me know if I made any obvious mistakes in this post, and also let me know about your progress.
Personally, I feel like I live in the feature. Live streaming to a global audience, from my own office room. Wow.
If you already run containers and even SQL Server in containers, this post is not for you. This is something to get started.
And I will start very basic. You heard the word “Container” and you heard it’s good. But you wonder, what the heck IS a container. Great. This is for you.
I created a video about creating your very first container. This post contains some more, and it’s a lot easier to copy/paste from a blog than from a YouTube video.
What the heck is a Container?
A container is a way to run a process, or a program. In my examples, that program is going to be the SQL Server executable. The surrounding operating system lends some resources. Like a namespace, so that whatever is running inside the container can’t see everything in the hosting operating system. Once inside the container, the processes can’t see what’s running outside of the container. The operating system controls how much resources the processes inside the container can use – how much CPU, how much RAM etc. Since the operating system gives the container some resources on its own, it can look to the processes running inside the container as if they are even running in a host of their own – with its own hostname.
I heard this is all Linux stuff, I don’t know how that works
It is true Containers is mostly a Linux thing. You can run Windows containers as well, but the Windows operating system isn’t as good as Linux at creating this isolated environment for processes, which means Windows containers are substantially larger. That means more time to create them and more resources to host them. Therefore, containers is mostly a Linux thing. But you don’t need to know all that about Linux. If you run SQL Server in a container, you need to know something about SQL Server on Linux. But not much really. If you run a .NET Core application in a container, you just need to know about .NET Core. The Linux operating system, and how to configure it to be able to run the containers, that’s what you have container software for.
How do I run a container?
To be able to run containers in Windows 10 or Windows 11, you need software to maintain and run the containers. I prefer Docker Desktop for Windows, which you can download from docker.com. You also need a Linux environment running inside your Windows operating system. Either in a Hyper-V VM or in Windows Subsystem For Linux ver 2 (WSL2). These are Windows features which you will simply enable. Once you have enabled them, you will configure Docker Desktop to use either Hyper-V or WSL2. If you run in Hyper-V, you don’t need to create, configure or even login to the Linux VM. Docker Desktop takes care of that for you.
Ok, I have Docker Desktop, now what?
Once you have installed and configured Docker Desktop, you’re ready to start playing with containers. I will use SQL Server containers. But there are container images for basically everything. In some of my demos, I use a .NET Core SDK container to build a .NET Core application, which I then run in an ASP.NET Runtime container. Imaging something that can run in Linux. That something can run in a Container, and there’s 99,9% chance someone else already wanted to do it and created a container image for it. And despite what some people may thing of people, people are mostly friendly and like to share things, so look and you’ll find.
Some simple docker commands to get you started
Fire up your favourite terminal and start playing. Here are some commands to get you started.
# Pull, or download if you will, the layers that make up the
# container image for SQL Server 2022, latest build.
# Think if "pull" as "download installation media". Or even
# "download a snapshot of a preinstalled VM with SQL Server"
# Only there's no VM, because a container is not i VM, it's just
# isolated processes running in Linux.
docker pull mcr.microsoft.com/mssql/server:2022-latest
# Use docker create to create a container from an image.
# If that image isn't already downloaded,
# docker create will take care of the pull for you.
# parameters to docker create
# -e Environment variables to create inside the container
# -p Port-mapping. Map local port X to container internal port Y
# -v Volumes. Mount a persistant docker volume to a path
# inside the container file system.
# Put the name of the image you want to create the container
# from last in the docker create command
docker create -e"SA_PASSWORD=Pa55w.rd" -e"ACCEPT_EULA" -p1450:1433 -v datavolume:/var/opt/mssql --name myveryfirstcontainer mcr.microsoft.com/mssql/server:2022-latest
docker start myveryfirstcontainer
# docker start will start a container created with docker create
# docker stop will stop a container that is running
# docker rm will remove a container. Stop it before removing
# docker ps will show you running containers
# docker ps -a will show you all containers
# docker run is a combination of docker create and docker start.
# You probably want to use the -d switch to start the container detached
# Otherwise your terminal will run the container process interactively and when
# you close the terminal, your container dies
docker run -e"SA_PASSWORD=Pa55w.rd" -e"ACCEPT_EULA" -p1450:1433 -v datavolume:/var/opt/mssql --name myveryfirstcontainer -d mcr.microsoft.com/mssql/server:2022-latest
# finally, docker exec. It will run a command inside the container.
# if you want to run it as "fire and forget", or rather if you want an unattended
# execution, you want to run it with -d, detached that is.
docker exec -d myveryfirstcontainer touch /var/opt/mssql/emptyfile
# Sometimes you want to run commands interactively inside the container
# Then you want a shell. Bash or sh for example.
# Then you want to run them with the -i and -t switches.
docker exec -it myveryfirstcontainer /bin/sh
Happy playing with containers. Once you have played some, you will want to learn some more. When that happens, there’s a chance I have written some more on the topic and you will return here. I of course didn’t learn in a vacuum. Andrew Pruski knows a lot more than I do about containers and what he writes and presents will take you to the next level once you start playing. Start on Andrew Pruskis website: DBA From The Cold | Ramblings on working as a SQL Server DBA
The title of this post: A while ago, I did a Teams presentation for my son’s class, about my occupation. And to make it a bit more fun, I told them I’m a Database Specialist and a YouTuber. The later didn’t amuse my son. He was upset when he came home from school. “You don’t even have 1000 subscribers on your channel, you’re not a ‘tuber’, he said.” I still don’t have 1000 subscribers, but it’s getting closer, so maybe I’ll have to start printing swag and call myself a SQL Influencer instead of a consultant soon 🙂
TL/DR; Keep videos short if you want viewers to watch the whole thing. That’s really hard if the video is a recording of a 60 minute long presentation 😂
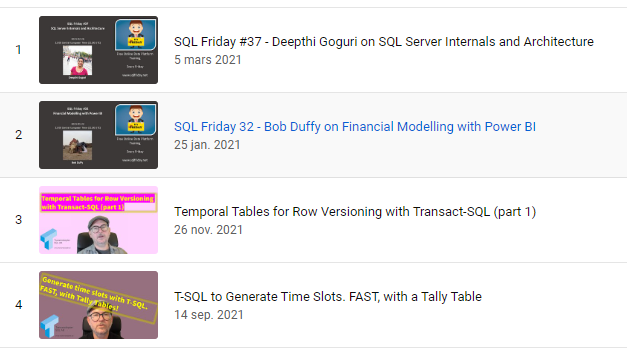
Since I started organising and hosting SQL Friday, I have recorded every presentation. Most of them are published on my YouTube-channel (the rest are editing-work-in-progress and will show up shortly).
“Rank” 3 and 4 are my own videos, so not SQL Friday Recordings. They are about Temporal tables and and about Tally tables.
YouTube studio offers some more analytics than just the views, and here it becomes interesting and actionable for content publishers. As a publisher, you probably want viewers to watch the whole video, right? Sorry for you, but that’s not going to happen. At least not all viewers. People are going to watch the beginning and then drop off. Or watch some sections but fast forward through other sections. Or watch 20 minutes, and then the phone rings and they shut down their browser etc.
What I found out is, publishing full episodes from SQL Friday is not ideal. SQL Friday presentations are on average just over one hour, including the after-presentation chats which I usually leave in the video. That’s almost the length of your typical Hollywood movie. And that’s honestly too long for a YouTube video. But what if my goal isn’t to get as many views as possible? I mean, of course I want everyone to watch and learn from the fantastic presentations that speakers have given to the SQL Friday members. But I realise that one-hour long videos about SQL Server has a somewhat narrow possible audience. So I’m happy if just a handful of people, who missed the live presentation, watches the videos end-to-end.
For Deepthis video about SQL Server itnernals, the average view time is 8 minutes 45 seconds. That’s only 13,4% of the total video, so it must be really bad, right? Not really. Or not necessarily. Because only 1/3 of the viewers watched past the first 40 seconds. That’s very, very typical for a YouTube viewer. You watch something, and when the video ends, you get a new suggestion. You start watching, and maybe, just maybe that wasn’t an awesome suggestion, so you skip to the next suggestion. So if viewers watch 13,4% of Deepthi’s video, and 2/3 drops off after less than 40 seconds, that means the 1/3 that stays past 40 seconds watch roughly 40% of the video. That’s a whole lot better than 13,4%, right?
Using YouTube Studio’s analytics section, you can go into depth with every video, and try to figure out what makes people loose attention, or keep watching. For real “tubers”, this will have a direct impact on income. For me, I don’t have the channel to make money on ads. But I do like it when the people who find the videos keep watching them, because that means they probably like the content and think they can learn something from it.
What’s the ideal video then? I have no idea to be honest 🙂 But it looks like at least “my” viewers stay on the video for a larger percentage of time if the video is around 10 minutes compared to 60 minute videos. So perhaps “Keep it short” is the advice? On the other hand, if the video is a recording of a 60 minute presentation, it’s pretty hard to make it 10 minutes long.
I recently started seeing lots of implicit conversions in execution plans in a system for which I oversee databases. Implicit conversions happen when two values with different datatypes are to be compared. Here’s first an example of implicit conversion that does NOT affect performance all that much. I’m running the query in the AdventureWorks2014 database.
What is Implicit Conversion? Is it good or bad?
SELECT
BusinessEntityID,
FirstName,
MiddleName,
LastName
FROM
Person.Person
WHERE
LastName='Sánchez';
What’s gonna happen when this query executes? The SQL Server Optimizer is going to find an index, ix_Person_LastName_FirstName_MiddleName with the names as key columns and BusinessEntityId on the leaf level (since it’s the clustered index, the clustering key is always included on the leaf level of non clustered indexes). So the optimizer is going to choose to do an index seek on that covering index. But before seeking into the index, SQL Server have to CONVERT values, because ‘Sánchez’ is a varchar value and the LastName column is an nvarchar column. So implicit conversion is going to happen. The optimizer is going to choose to convert the varchar value to nvarchar and then perform the seek operation. The reason for that is that nvarchar has higher precedence than varchar. This makes sense. Nvarchar can store text that varchar can’t. Doing it the other way around – convert nvarchar to varchar – would result in loosing some data in the conversion and therefore give us the wrong results.
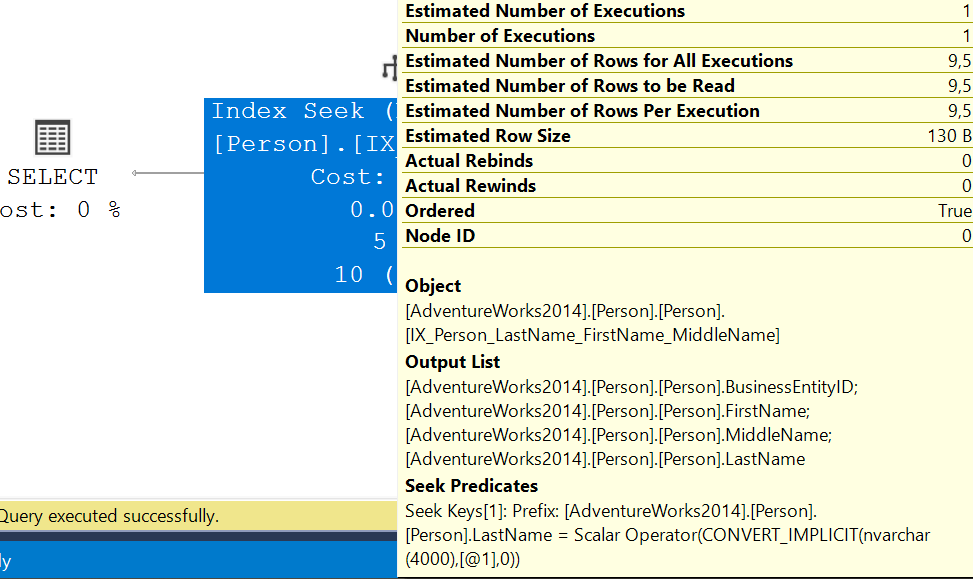
Here’s where you can see implicit conversion in the execution plan.
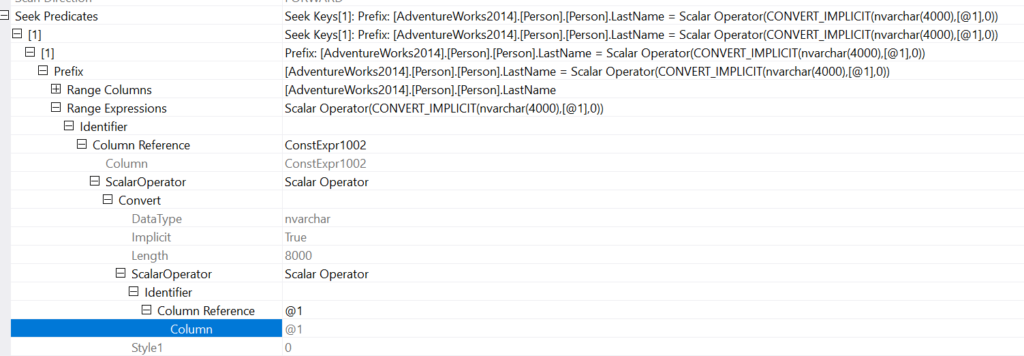
Hover on the Index Seek operator and you’ll see that the varchar value is converted with CONVERT_IMPLICIT to nvarchar(4000). You could also right-click on the operator and look at properties to find out more. Properties for the Seek Predicates of the Index Seek operator.
Will this implicit conversion affect the performance of our query? No, it won’t. At least not noticeable. Our constant is converted to nvarchar(4000) and then it can be used to seek into the index.
Let’s look at a more problematic example. Let’s run two queries against the Sales.Customer table.
SELECT
CustomerId,
AccountNumber
FROM
Sales.Customer
WHERE
AccountNumber = 'AW00000013';
SELECT
CustomerId,
AccountNumber
FROM
Sales.Customer
WHERE
AccountNumber = N'AW00000013';
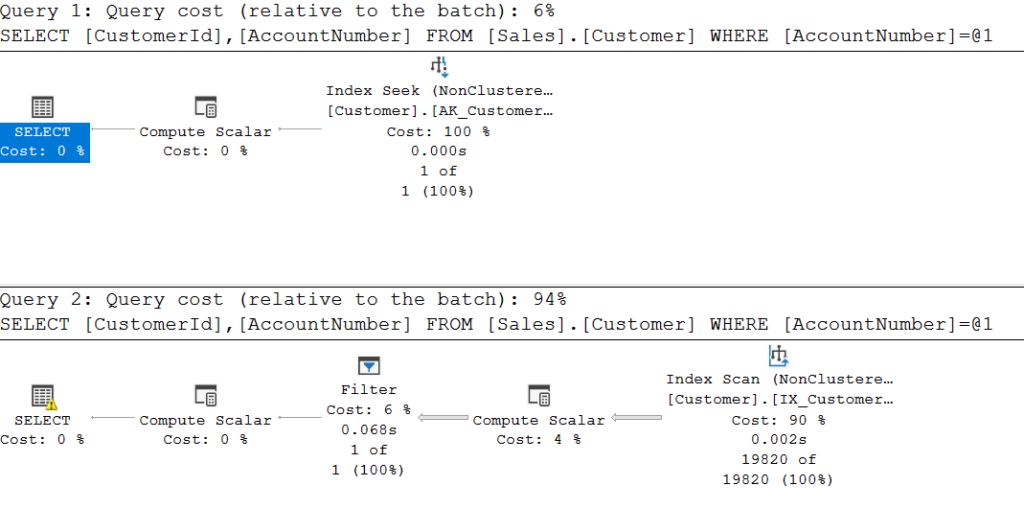
What do you think will happen with these two very similar queries? The first one will perform an index seek into the index AK_Customer_AccountNumber. The second one will perform an index scan of the index AK_Customer_AccountNumber.
And it’s not only seek vs scan. We get an extra compute scalar and a filter in the lower plan. But the important operator is the Index Scan and the Filter operators.This is in the tooltip of the Filter operator and the cause of bad performance.
What happens here? The upper query performs just the way we expect. Use the index, seek into it. But in the lower query, we send in an nvarchar value. Since the table column is varchar, we get implicit conversion on the COLUMN, not the parameter/constant expression. This is really bad. It means we are scanning every single row of the table and pass it on to the FILTER-operator, where the predicate is evaluated.
Dapper
Now we have looked at what implicit conversion is. We also now know a little more about when it can be bad for us.
I said in the beginning that I saw implicit conversion in Query Store. And it wasn’t the good kind of implicit conversion, where parameters or constant values are converted. I saw implicit conversion on the table side of things, resulting in index scans.
Investigating things got me to queries sent from a service, in a code path using Dapper. Dapper is a library that can be used to map database results to application code objects. It’s relatively easy to use and lots of developers favour it vs just using SqlClient.SqlCommand or other frameworks like Entity Framework.
Dapper. And parameters.
Dapper provide a really simple way to pass parameters to queries. It looks a little something like this:
var template = new SalesCustomer { AccountNumber = "AW00000013" };
var parameters = new DynamicParameters(template);
var sql = "select CustomerId, AccountNumber from Sales.Customer where AccountNumber = @AccountNumber";
using (var connection = new SqlConnection(connString))
{
var customers = connection.QuerySingle<SalesCustomer>(sql, parameters);
}
See how simple the parameter passing is? Just create a template from a SalesCustomer class with a specific AccountNumber and create a DynamicParameters result set from this template. But the parameters aren’t strongly typed. This means Dapper/.NET will choose a datatype for us. This will translate to an sp_executesql call with defined parameters. AccountNumber will be passed in as an nvarchar(4000) parameter to the query.
How is this bad?
As we saw in the execution plans above, when we send in an nvarchar value to a query that uses it to compare it to a varchar column, we will get implicit conversion on the table side of things. SQL Server will scan every row of the index and then apply the filter predicate. That’s not an effective use of a covering index. Effective use would have been an index seek.
What should we do then?
We saved a couple of characters of code by not specifying the datatype for the parameters when we created the Dapper code. But we make the database suffer every single time we run the query. What’s the correct way of doing this?
In Dapper, we could instead create an empty parameters collection and use the Add-method to add parameters, with datatype, direction and more. In Dapper, it would look a little something like this.
var parameters = new DynamicParameters();
var AccountNumber = "AW00000013";
parameters.Add("@AccountNumber", accountNumber, DbType.AnsiString, ParameterDirection.Input, AccountNumber.Length);
var sql = "select CustomerId, AccountNumber from Sales.Customer where AccountNumber = @AccountNumber";
using (var connection = new SqlConnection(connString))
{
var customers = connection.QuerySingle<SalesCustomer>(sql, parameters);
}
In the above example, we explicitly defines the AccountNumber parameter as DbType.AnsiString, which will translate to varchar in SQL. Using DbType.String would give us an nvarchar parameter. But in our case, we want to pass a varchar parameter. And while we’re at it, we’re setting the LENGTH of that varchar parameter. Because otherwise it’s going to be sent as varchar(8000). For the comparison itself this doesn’t matter too much. But the larger datatypes sent in as parameters, the larger the memory grant you’ll need to execute the query. And if you’re going to explicitly set the datatype, you might as well explicitly set the length too.
Conclusion
Be explicit. A few extra lines of code could potentially save you from that 2AM call when you’re on call, because that one important batch brought the database on it’s knees. Use AnsiString for varchar and String for nvarchar.
I’m trying to summarise 2020. Don’t know how to describe the year. It’s been…. rich in content.
This post will be slightly unstructured as I’ve tried to write down just the things
Picture: mr_write at morguefile.com
New Year, New Opportunities
2020 started pretty normal. After some time off with the family, I started a new, one-year consultant assignment with the company I was employed at before I started my company. Though I had been away for some years, it was nice to be back. A lot had changed, but even more was the same. Most of all, it was nice to catch up with some very awesome people that I hadn’t seen for a couple of years.
I had set out to visit more SQL Saturdays and other conferences than previous years, and I started with a trip to SQL Saturday Vienna on January 24th (yes, that’s a Friday, the Austrians don’t know their weekdays like the rest of us😊).
Covid-19
I’m not sure when we first heard about Covid-19, but it can’t have been long after SQL Saturday Vienna. It started as something in China. Then there were some travel restrictions and before we knew it, several european countries were reporting the virus spreading out of control.
In my team at work, key people were sent home to work from home, to make sure we could maintain operations if the virus took out the whole office. Within two weeks, the rest of us were sent home. This must have been by the end of March. Initially, we were meant to work from home for a few months, perhaps until summer vacations. And when people came back from summer vacations, the word was that we would be slowly moving back to working in the office instead of working from home. And then came the second wave.
Since end of March, I haven’t set foot in my client’s office. Instead, I rented a small office room in my home town, early November so that I wouldn’t have to spend afternoons with “daddy is in a meeting, please keep your voice down” to my kids. After all, the house is there home more than it was my office. It feels nice to leave the house and go to the office. There are a few more persons on the office floor where I rent my room, on a busy day there are as many as four or five. We keep the distance, and I work with the door to my room closed, so it feels safe.
This pandemic will be over at one point. We don’t yet know when. Vaccine is being distributed as I write, but it will take months before enough people get the vaccine before we can relax.
I think this pandemic and the timing of it will change the way many of us work. Obviously, some jobs can’t be done remotely. Teaching and learning will be mainly an in-person activity. Construction workers, nurses and doctors can’t work from home. But for all of us that CAN work from a remote location, I think the “new normal” will be remote work, with fixed days when we meet in a common location. At least I’m not ready to go back to spending 12,5 hours per week commuting anytime soon.
One year working with this client has been really amazing and I’m happy to have signed a contract for 2021 as well. It’s been a tremendous team work, when we have migrated lots of systems to new infrastructure, with the goal of improving documentation and become more cloud-ready with the applications. I have become more fluent with Powershell and I have learned a lot about networking, DNS and load balancers than I anticipated. And of course, I have tuned a SQL statement or two. After all, DBA is my main reponsibility within the team.
Data Weekender
With SQL Saturdays cancelled or postponed, there was a vacuum in the Data Community. Speakers didn’t have conferences to attend and data professionals had far less learning and networking opportunities when countries went into lockdown mode. I responded to a tweet from Kevin Chant, where he asked if anyone was interested in trying to organise a virtual conference. Damir Matesic, Gethyn Ellis, Asgeir Gunnarsson and Mark Hayes also replied to Kevin’s tweet.
We had a first zoom meeting to discuss the format of a virtual conference. Mark did some magic with a cool picture from Kevin’s honey moon, where he was sitting in a camper van, and we decided the name of the conference would be Data Community Weekender Europe (which was later changed to just Data Weekender). https://www.dataweekender.com
On this first zoom-call, we also decided on the date for the first edition of Data Weekender. And looking back, I can totally see how unrealistic it was. We were to organise a conference within 30 days, and all we had was a name and a cool picture.
But we did it. We opened up the Call for Speakers and left it open for only ten days, April 8 – April 17. We organised Data Weekender on a zero budget, which meant we didn’t have a marketing budget. Instead, we relied on Twitter and LinkedIn to spread the word. And it worked! We anticipated a conference with two or three tracks but we got 196 submissions from 76 individual speakers and ended up running the conference on six tracks with a total of 42 sessions.
The first edition of Data Weekender was May 2nd and we had roughly 600 individuals participating in the conference.
On October 17th, we did #DataWeekender #TheSQL, with a few more sessions and with some lightning talks. More or less the same number of participants, which we think was a pretty good result, as by then, there were many, many more virtual events being organised.
Thank you Kevin, Damir, Gethyn, Asgeir and Mark! I look forward to The Van running again in 2021!
SQL Friday
Just after the first edition of Data Weekender, I went public with my idea to run a weekly online lunch event, SQL Friday (https://sqlfriday.net) . I didn’t publish a Call for Speakers for the whole season, but instead made sure I had speakers for the first few weeks, started tweeting about it and hoped for the best.
And it worked out pretty well. Sql Friday episode #1 had Damir Matesic as the guest star. The topic was T-SQL and JSON and it had 120 registered attendees.
The format of SQL Friday is casual. There’s no powerpoint template. There are no sponsors to thank (my company is organising the event and people participating is enough thanks) and speakers can choose to do 60 minutes of demos or 60 minutes of just powerpoint slides. It’s all up to the speaker.
There have been a couple of “bloopers” this season, and I’m sure we will have more of them in 2021. When Mark Hayes had some problems with his audio, I told him for a minute or two that we could now hear him, while he was changing settings. But I was muted, so he didn’t hear me. But the worst one was probably when Gianluca Sartori got a blue screen in the middle of a demo. “Gianluca, hello, are you there?”. But he was back on the call within five minutes and continued like nothing happened. Impressive!
I want to thank all the speakers and attendees for joining me for 29 fridays in 2020. The schedule for January-June 2021 is published and we have 25 really good sessions to look forward to, the first one being on January 8. If you haven’t already, join the Meetup group at https://meetup.com/sql-friday.
SQL User Group activity
With in-person events out of the question, SQL Server Usergroup Sweden went virtual, as did many other groups. And we’re still virtual, at least for the coming few months. Lately, we have started having bi-weekly user group meetings, even when there are no speakers. We just meet and have a chat about work and personal life. It’s nice to see some familiar faces and get that important networking going.
Public speaking
With in-person events cancelled, I have had more opportunities to speak at events and user groups I wouldn’t have been able to visit otherwise. For example, I did a talk about dbatools for the Quad City User Group in April, and another one about partitioning for the PASS380-group, the day before. It was middle of the night for me, but I’m a night owl anyway so it was all right. I “went to” Singapore in the autumn and I spoke at Data Platform Summit in the winter. And I’ve done a few Virtual SQL Saturday talks as well.
In september, I did an in-person talk at SQL Saturday Gothenburg. There were not many attendees, I think Mikael who organised the event had set a limit of 50 attendees. But regardless the size of the event, it felt so, so good to be in a classroom and actually meet people, to be able to stay for an informal Q&A-session in the hallway after the talk, and to be able to hang out in the hotel bar with Asgeir Gunnarsson and Erland Sommarskog in the evening.
MVP
I can’t summarize 2020 without mentioning I was awarded Microsoft Most Valuable Professional. I know a lot of MVPs say the same, but I was honestly not expecting this award. Thank you so much Damir Matesic for nominating me, and thank you Microsoft for the honor. I’m gonna do my best to continue contributing to the Data Platform community. And perhaps a few contributions to the Powershell community in the year to come.
PASS
The sad news about PASS taking its last breath on January 15th 2021 leave more questions than answers. Will anyone take over SQL Saturday? Will anyone take over PASS Summit, the largest Data Platform conference in the world? And do we need a global organisation for the Data Platform community? We will see. But I do know that PASS driven events took me to where I am today. My first Data conference was SQL Rally Nordic, in Denmark. That’s when I started thinking about public speaking. A PASS Usergroup was my first SQL related presentation. And PASS SQL Saturday was the first time I presented on a conference.
Thank you PASS for all these years. And thank you all amazing people within the Data Community. #SqlFamily will remain, we’re yet to see in which shapes.
Health
Despite all the professional development and all the community work I have done in 2020, the most important has been my personal health. After some stressful years of starting my company, commuting for hours every day and working a lot more than what’s healthy, I see the period of working from home as a real blessing. I mean, I don’t see covid-19 as a blessing, but the consequences has been that I’m home a lot more than before, I spend a lot more time with my family and I picked up running again.
Running. That used to be an important part of my life. But I haven’t prioritised it for years. I have eaten unhealthy food and I have gained weight. In just a few years, I put on 25kg. When I started working from home, I weighed more than 100kg, with a Body Mass Index of 32,5 (obesity). After working from home (or from my nearby office room), I have lost 14kg and my Body Mass Index is now at 28. It’s still considered Overweight, but it’s a lot better than 32,5. And I love running again. The last seven days of 2020, I have run every day. And I’m not finished. My goals for 2021, which I’m sure I will meet, is to loose another 10kg and to run a marathon before 2021 is over.
2021
I don’t know what 2021 will bring, other than what I said in the previous paragraph. I do know that there will be abother Data Weekender event. And that there will be SQL Friday events. I’m sure before 2021 is over, there will be in-person Data events to visit as well. I have already made a promise to be on the front row when Nikola Ilic makes his first in-person conference presentation, so I guess that’s one conference (wherever it may be) that I will visit.
But the biggest take-away from 2021 is to not plan too far ahead. Plans change. Some changes are minor, some or huge. And we will see change in 2021 as well.
This post is a contribution to this month’s T-SQL Tuesday (hashtag #tsql2sday on Twitter). Glenn Berry is this month’s host, and the topic is: “What you have been doing as a response to COVID-19”, as described in Glenn’s blog post T-SQL Tuesday #126 – Folding@Home.
I’m thinking of two contributions I’ve been working on for the community we know as SQL Family. One being planned, TGI SQL Friday, a friday lunch talk about Microsoft Data Platform, with one other member of the SQL Family as a guest. But this post is going to be about Data Community Weekender Europe, better known #DataWeekender.
I had been looking forward to 2020 as my most active year as a speaker. I have been in contact with local user groups in Europe, to whom I was going to pay a visit. I have submitted way more session abstracts to SQL Saturdays and other conferences than any previous year. Then came Covid-19. SQL Saturday Croatia was postponed. SQL Saturday Stockholm was cancelled. Trips to user groups were obviously cancelled. You get the pattern.
When looking at Twitter, I saw Kevin Chant (B | T) gathering interested parties to a virtual conference. Two tweets later, I was one of the six organisers of Data Community Weekender Europe, better known as #DataWeekender or Data Weekender. This was April 9th. The other organisers had already come up with the name of the conference and setup Call for Speakers in Sessionize. After that, it’s been hard work.
We had a number of challenges to overcome, many of them technical.
But before getting any of that up, we needed speakers. Without speakers, there wouldn’t be much of a conference. A discussion we had on an early stage was: “Should we as organisers submit sessions to the conference?” We decided we could, but wanted to wait to see how many abstracts were submitted before deciding. We had a record short Call for Speakers period, from April 8th to April 17th. That’s ten days. We felt it was a bit short, but to realistically have the conference on May 2nd, we couldn’t extend CfS-period further. Thus the decision we would all submit a session each if needed, to make it at least two tracks on the conference.
Wow. Were we wrong. There was absolutely no need to submit sessions ourselves. It turns out we had excellent channels to reach potential speakers, and our tweets and LinkedIn-posts about the conference reached out amazingly well (thank you everyone who tweeted and retweeted on an early stage!). By the end of CfS-period, we had almost 200 excellent sessions to choose from.
Next dilemma: With so many fantastic session abstracts submitted, from 76 speakers, how on earth were we to select sessions? We had discussed running two, maybe three tracks. We ended up with six parallel tracks, a total of 42 really good sessions, many of them from the most well-known speakers in the industry.
April 22nd, we made the schedule public. By then, we had roughly 150 registered attendees. We are all experienced community organisers and we know the no show-rate on any free event is 40-60%. That would leave is with roughly 75 attendees, for a six-track conference. Not impressive. The day we published the schedule, we got another 80 or so attendees registered. But we still had a long way to go and the days following April 22nd were pretty slow on registrations (50 or less per day).
Then something happened on April 27th, less than a week before the conference. We got 155 registrations on the same day. And an average of 100 registered attendees per day the following days.
This didn’t just happen. Between the six of us on the organising team, we probably tweeted 500 times with the hashtag #DataWeekender. We Posted around 100 LinkedIn-posts. We got in touch with all user groups we could find and told them about the event. We told people on the largest Facebook-groups about the event. Our Twitter account @DataWeekender started sending out tweets with dance-gifs every time we hit an even 50 or 100 registered attendees. And those tweets reached out.
I have to mention the help we got from volunteers as well. Both with promotion before the conference, but perhaps most importantly, all the help we received on the day of the event. If it’d just been the six of us, we would have been moderating one track each all day, without any way to answer support speakers during the day. We had setup WhatsApp-groups for the speakers of all the six tracks, to quickly reach speakers and give them a direct contact with one of the organisers. But without help with session moderation, it would have been useless, nobody can multitask that much in the middle of an ongoing session. So a yuuuuuuuuuuuuge Thank You to all the volunteers! ❤❤❤❤❤❤❤
Now the event day seems long gone, though it’s just ten days ago. We have been distributing speaker feedback to all the speakers and we evaluated the event feedback we got. And we are already talking about next iteration. Should we run it in another timezone? What else do we need to change (not much tbh, we feel really comfortable with the format). When will it happen? Does that make you curious? Sign up on the MeetUp-group Data Community Weekender and you’ll be the first to know!
Until next time: Thank You everyone who participated in any way to make the inaugural a complete success!
Organising team for Data Weekender:
Magnus Ahlkvist (B | T) Kevin Chant (B | T) Gethyn Ellis (B | T) Mark Hayes (B | T) Asgeir Gunnarsson (B | T) Damir Matesic (B | T)
The forced upon social distancing is new and – to say the least – different! For me, this means I’m exploring my local surroundings (we have really beautiful walking and running paths close to my house) a LOT more than usual. I’m spending my lunches running instead of looking for the best indian restaurants around the office.
Data Community Weekender Europe conference May 2nd, Call for speakers end on April 17th
A big part of my – and thousands of other SQL Server professionals – life is the Microsoft Data Platform Community – the SQL Family. That has obviously also seen some recent changes. I was gonna spek on SQL Saturday in Zagreb and Stockholm, I planned to go to London for SQL Bits and I had ideas for the SQL Server Usergroup which I’m co-leading. None of that happened. Speakers around the world tell the same story.
But instead of letting Nothing replace all of that, new things are happening. I’m speaking in Ohio next week. Or at least I’m speaking to user groups whose members live in Ohio. Online obviously, I’m not travelling to Ohio for a tuesday and a wednesday session. For the swedish SQL Server Usergroup (SQLUG Sweden), we were delighted to have Mark Hayes (T) speak about Power Platform the other day (Thanks Mark!).
Another thing which is happening is that online conferences are popping up. Me and a group of SQL Community organisers decided it’s too booring to just wait for social distancing rules to pass. That’s how Data Community Weekender Europe started. It’s really a crazy idea. From when Call For Speakers page came up, to when the conference happens (May 2nd), it’s roughly three weeks. In that time, we in the organising committee need to market the event to potential speakers, get session submissions in in a timeframe which is one tenth of a normal conference, do session selection, market the event to attendees and get the technical platform in place. Plus potentially recruiting volounteers for event day. But guess what? We WILL do it. We already have some great session submissions in and we’re working out the technical platform. We in the organising committee are all seasoned SQL Community organisers. We have pulled off crazy schedules before, though perhaps not at this scale. But we WILL pull it off. Stay tuned for the attendee registration. It will be announced here and on social platforms.
If you’re a Microsoft Data Platform speaker, send in your submission! It won’t be like attending a physical conference. The speakers’ dinner will be much less crowded, you’ll have to have your post session beer on your own. But you’ll be able to provide your amazing content. So thank you in advance, for submitting to this crazy idea of a conference!!